II.A. Addressing large non-specialist audiences
This includes traditional lecture-based class presentations as well
as broadcast video. Shrink-wrap applications suffice for most of this sort
of rehearsed communication. Their major shortcoming at the moment is relatively
primitive inter-operation with each other and with networked information
sources.
II.B. Communicating with peers
An exciting, and controversial, issue is the changed nature of publication.
Publishers of academic journals are worried about being cut out of the
loop, when their remaining raison d'é tre -- conferring authority
-- is removed by distributing editorial and peer review in a secure way
to the Net. Paul Ginsparg's High Energy Physics server in New Mexico is
a model of one emerging paradigm. Many other variations of electronic journals
are being established.[7] (See the note about graded
model of publishing / broadcasting.) Digital signatures, time-stamping
and editorial policies promise to resolve many of the technical issues.
The interesting questions, I believe, lie in the emerging fusion of computational
scripts with traditional writing.[8] Live texts written
in Mathematica provide examples in well-defined domains, but as authors
jump into the World Wide Web (WWW) and HTML[9], they
will find themselves in a new twilight zone.[10]
But even given MBone live video technology or its less sophisticated
cousin, CU-SeeMe, "better communication" may be insufficient justification
-- from an academic point of view -- for the large cost of installing and
maintaining such technology, unless we can also use some of the electronic
medium's power to transmit abstract, structured information which is interesting
to scholars. Not only do we wish to draw nuances from our conversational
partner's face, we also wish to exchange and manipulate spreadsheets, architectural
walk-throughs and relational models, through a variety of modalities. Designers
of scholarly spaces need to augment commercial software to support scholarly
"data" structures which are not anticipated or supported in the wider market;
for example: searchable musical scores, meta-dictionaries customizable
to various natural languages, symbolic algebra expressions, etc. There's
a rich history of technology for structured communication formats; Don
Knuth's TeX, and Leland Smith's musical score software are two non-commercial
products seminal in their respective fields of application.
II.C. Mentoring
In the academic practice of mentoring, nothing, I believe, should replace
direct human contact, simply because most humans are social animals and
students must acculturate within their chosen academic or professional
circles. Some of this acculturation may be smoothed by communication technologies
(eg. live/deferred video-walls), or shared whiteboards, taking advantage
of the Eliza effect.[11]
As I intimated in II.B, much technology is justified today on the grounds
that it will help us communicate better. But communication is only one
aspect of scholarly work. At least paradigmatically, a large part of scholarly
work is concerned with abstraction, cogitation, fantasy, analysis, understanding:
the creation of knowledge in humans. Let's look at examples from
the domain of personal research.
Some modes of scholarly work require close analysis of a few entities
(scanning a poem, turning a pot-shard, color-rotating a watermark) whereas
other modes require broad "reading" over large ranges and types of sources.
These sources are not just bibliographies or abstracts, but full content.
In the course of writing a 30 page article, one scholar might sift through
dozens of books and several cabinets full of manuscripts, some of which
may not be touched by anyone else for a generation.[12]
I claim that most shrink-wrap applications do not go deep enough in
serving either of these polar modes. Shrink-wrap presentation software
do not suffice (though appropriate for formal addresses - see II.A &
B) because they are not designed for such practices. Take as an example,
a popular word processor. Very likely it does not come with a Greek prosody
analysis function[13] or a classical Chinese parser.[14]
A typical news service will not provide means to acquire and systematize
accounts and models of ballgames in Mayan culture. On the other hand, many
special research tools (eg. ArcInfo GIS, or SPSS or computer graphics animation)
are vertically integrated into particular computer systems and not available
in some form over the net to a range of scholars' desktops.[15]
Many scholars theorize or build models. In some disciplines, scholars
occasionally build or use computable models[16], whether
or not they explicitly think they do this. Formal computer-augmented tools
derived from statistics, mathematical modeling or database techniques may
now be sophisticated enough to be usable by and useful to scholars outside
the disciplines which traditionally use computable models, such as engineering
and economics.[17] Model building in scientific disciplines
is limited by, among other factors, the need to translate between formalisms
such as mathematical representations and procedural computer languages.
Another limitation is the welter of graphics environments, few of which
are well suited for scientific experimentation as opposed to entertainment
or presentation. A third limitation is that it is not obvious how to smoothly
scale models from back-of-the-envelope calculations to large-scale computation,
though many scale-specific tools are now available. As an example, contrast
the habits of MathSciTech users with those who use supercomputers.
Some limited reasoning in abstract domains, such as mathematics or linguistics
can be automated[18], but here the bottlenecks are
quite different. The informal formalisms used by human experts in these
domains are far more expressive than artificial languages, so I'm afraid
we'll just have to wait a bit longer until computers can significantly
augment reasoning (as distinguished from communication or composition).[19]
There are more fundamental objections to the possibility of synthetic mathematical
reasoning, but pace Roger Penrose, I speak here of a more modest
need for something like a mathematician's secretary, who can remember certain
high-level theorems and automatically apply certain derivations to a formally
described object.
In this context, writing, or more generally composition (putting your
thoughts into text, clay, music, code, etc.) can be a form of personal
research. New technology may provide alternate paths from private composition
to public dissemination in the sense of II.B.[20]
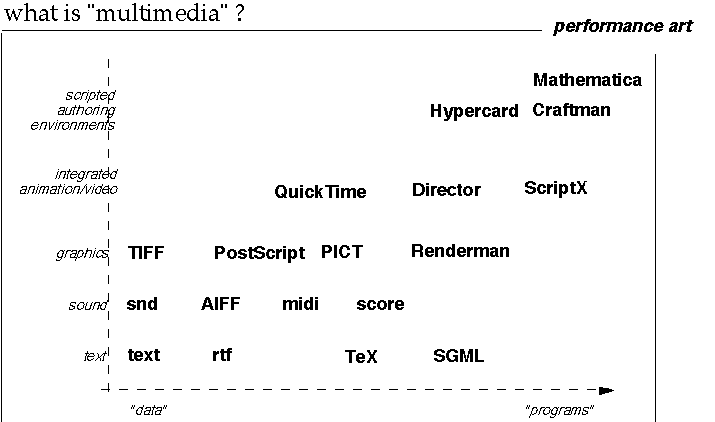
Almost none of these scholarly needs mentioned in II.D are met by most of the so-called "multimedia" technology, which in 1994 happens to be equated to digital video. (See figure "What is Multimedia?")
Figure 1. What is multimedia? In this schematic, the horizontal axis marks degree of embedded logic, and the vertical axis marks various modalities. Looking over the range of renderable information, we see that " multimedia" is not much more descriptive than "media." [21]
Practices such as abstraction, deduction and metaphorization deserve special attention in the design of scholarly spaces. As a rule, a sign of the immaturity of a technology is an emphasis on mimetic fidelity. I call this the mimetic fallacy.[22] In the field of computer graphics, years ago, the buzz word was photorealism. In 1994, multimedia technologists compete on who can deliver the most bits/second on the widest, deepest, most color-faithful screen. Abstraction, reasoning, and imagination, could be served better by richer transformation spaces rather than by mimetic fidelity alone. Of course, technology ought to be able to reproduce "the physical world" as faithfully as possible upon demand, but this is an obvious goal of engineering.
We should, in designing scholarly spaces, be examining much more sophisticated
practices and tools than mimes of analog media. Sources include cultural
studies, cognitive sciences, computational linguistics, symbolic algebra,
music composition, and scientific visualization.
With these scholarly practices in mind, what principles can designers
and developers use to guide the construction of scholarly workspaces?
[7] Cf. Future of Mathematical Communication (http://www.msri.com/fmc/fmc.html)
[8] Within the mathematical sciences, TeX was the closest to such a fusion form, but was rarely viewed as a computing medium except by aficionados.
[9] HTML is the HyperText Markup Language in which WWW documents are written.
[10] Just as word-processors made it possible for non-professionals to fiddle endlessly with fonts and rulers, HTML further enlarges the design space, which is not an unmixed blessing to scholars.
[11] Eliza was a well-known AI program which, despite its simple response-construction rules, was able to elicit a few surprising conversations with humans. Some people found it easier to "confide" in Eliza than in a human therapist.
[12] We need a digitization service which would essentially allow a scholar to scan any analog item of interest into a structured format (eg. RTF, Postscript, Excel). This must be casual, cheap and complementary to formal, archival collection development. This must be as easy as bringing a laptop into the stacks to take notes. There may be "non-numerical" methods which are nonetheless "computable." I name some methods here, but will defer discussion for other, discipline-specific forums.
[13] As in Greg Crane's Perseus system for Greek and Roman literature.
[14] As in the Academia Sinica's Chinese Corpus database.
[15] Why is this important? In a given cell of an organization, it may be more efficient to invest in a heterogeneous distribution of resources which are then shared. Rather than buy everyone in the family a pick-up truck, maybe one pick-up, one Fiat Cinquecento and 4 bicycles to share would be more practical. Similarly, with network delivery of data and compute services, it may be more practical to ship some work off to another station to be performed with the results reported back. This sort of distributed computation is old hat to computer scientists and engineers but still uncommon in the general scholarly community.
Granularity is a key factor, however. We saw that batch-mode supercomputer processing failed even the majority of the scientific community for many reasons related to grain-size and centralization. The distributed model now becoming feasible works at a far finer grain in time as well as task, and should for the most part be fairly transparent or controllable by the individual. Example: if I wish to OCR all the articles which were faxed to me for a book, I may choose to invoke an OCR service which would do its job on a centrally administered compute server, leaving me free to continue my work on a lightweight mobile computer.
[16] By computability I intend more than numerical analysis, of course. This includes any methods which use algorithms that can be effectively computed in present-generation technology. So this excludes, for now, stylistics on music or speech, but includes limited extraction of semantic nets from text.
[17] I am by no means advocating the indiscriminate use or universal utility of quantitative model-building, particularly in disciplines such as mathematics or literary studies which rest on alternative modes of discourse and reasoning.
[18] Examples: P. Sells' Syntax Workbench; J. Barwise and J. Etchmendy's Turing, Tarski and Hyperproof programs; Geometer's SketchPad, ScratchPad (AXIOM), Mathematica, Maple.
[19] There are a few possible routes to the future, such as Mathematica or the language M. See also remarks on computable text in III.B.
[20] I do not claim by any means that research or learning can be automated in a vulgar sense! In fact, this is nonsensical when we are speaking of the knowledge attainment by humans rather than their proxies. Nor do I claim that computer tools or computational methods can be propagated willy-nilly in all disciplines. Just as sprinkling "workstations" into faculty offices yielded little fruit, transplanting uncontextualized computational methods or tools into scholar's hands will yield little scholarship.
[21] The "multi" in "multimedia" is merely an artifact of primitive computer technology. Until recently, software could present information in only one modality: pure text, pure graphics, etc., very unlike the perceptual world inhabited by most humans. Even now "multimedia " connotes a gaudy collage. For all these reasons, I prefer to drop the prefix and simply use the term "media" to indicate any renderable data.
[22] Martin Jay provides a wide-ranging review of the critiques of ocularcentrism -- perhaps the most egregious species of mimetic fallacy in Western culture -- in Downcast Eyes-- The Denigration of Vision in Twentieth Century French Thought (1994).